Proiectarea autobuzelor I / O reprezintă arterele computerului și determină în mod semnificativ cât și cât de repede pot fi schimbate datele între componentele individuale enumerate mai sus. Categoria de top este condusă de componentele utilizate în domeniul calculelor de înaltă performanță (HPC). Începând cu mijlocul anului 2020, printre reprezentanții contemporani ai HPC se numără produsele acceleratoare pe bază de GPU Nvidia Tesla și DGX, Radeon Instinct și Intel Xeon Phi (a se vedea [1,2] pentru comparații de produse).
Înțelegerea NUMA
Non-Uniform Memory Access (NUMA) descrie o arhitectură de memorie partajată utilizată în sistemele contemporane de procesare multiplă. NUMA este un sistem de calcul compus din mai multe noduri individuale în așa fel încât memoria agregată este partajată între toate nodurile: „fiecărui CPU i se atribuie propria memorie locală și poate accesa memoria de la alte procesoare din sistem” [12,7].
NUMA este un sistem inteligent utilizat pentru conectarea mai multor unități centrale de procesare (CPU) la orice cantitate de memorie disponibilă pe computer. Singurele noduri NUMA sunt conectate printr-o rețea scalabilă (magistrală I / O) astfel încât un procesor să poată accesa sistematic memoria asociată cu alte noduri NUMA.
Memoria locală este memoria pe care CPU o folosește într-un anumit nod NUMA. Memoria străină sau de la distanță este memoria pe care o ia un procesor de la un alt nod NUMA. Termenul raport NUMA descrie raportul dintre costul accesării memoriei străine și costul accesării memoriei locale. Cu cât raportul este mai mare, cu atât costul este mai mare și, prin urmare, este nevoie de mai mult timp pentru a accesa memoria.
Cu toate acestea, durează mai mult decât atunci când acel CPU accesează propria memorie locală. Accesul la memorie locală este un avantaj major, deoarece combină latența scăzută cu lățimea de bandă mare. În schimb, accesarea memoriei aparținând oricărui alt procesor are o latență mai mare și o performanță mai mică a lățimii de bandă.
Privind înapoi: Evoluția multiprocesoarelor cu memorie partajată
Frank Dennemann [8] afirmă că arhitecturile moderne de sistem nu permit cu adevărat accesul uniform la memorie (UMA), chiar dacă aceste sisteme sunt special concepute în acest scop. Pur și simplu vorbind, ideea de calcul paralel a fost de a avea un grup de procesoare care cooperează pentru a calcula o sarcină dată, accelerând astfel un calcul secvențial altfel clasic.
După cum a explicat Frank Dennemann [8], la începutul anilor 1970, „necesitatea sistemelor care ar putea deservi mai multe operații simultane ale utilizatorilor și generarea excesivă de date a devenit generală” odată cu introducerea sistemelor de baze de date relaționale. „În ciuda ratei impresionante a performanței uniprocesorului, sistemele multiprocesor au fost mai bine echipate pentru a face față acestei sarcini de lucru. Pentru a oferi un sistem rentabil, spațiul de adrese de memorie partajată a devenit centrul cercetării. La început, au fost susținute sistemele care utilizează un comutator transversal, însă această complexitate de proiectare a fost scalată împreună cu creșterea procesorilor, ceea ce a făcut sistemul bazat pe magistrală mai atractiv. Procesoarele dintr-un sistem de magistrală [pot] accesa întregul spațiu de memorie trimițând cereri pe magistrală, o modalitate foarte rentabilă de a utiliza memoria disponibilă cât mai optim posibil.”
Cu toate acestea, sistemele informatice bazate pe magistrale vin cu un blocaj - cantitatea limitată de lățime de bandă care duce la probleme de scalabilitate. Cu cât sunt adăugate mai multe procesoare la sistem, cu atât este mai mică lățimea de bandă per nod disponibilă. În plus, cu cât sunt adăugate mai multe procesoare, cu atât autobuzul este mai lung și cu atât este mai mare latența.
Cele mai multe procesoare au fost construite într-un plan bidimensional. CPU-urile trebuiau, de asemenea, să aibă controlere de memorie integrate. Soluția simplă de a avea patru magistrale de memorie (sus, jos, stânga, dreapta) la fiecare nucleu al procesorului a permis lățimea de bandă disponibilă complet, dar aceasta merge doar până acum. CPU-urile au stagnat cu patru nuclee pentru o perioadă considerabilă. Adăugarea urmelor deasupra și dedesubt a permis autobuzele directe către procesoarele opuse diagonal, pe măsură ce cipurile au devenit 3D. Plasarea unui procesor cu patru nuclee pe o cartelă, care apoi s-a conectat la un autobuz, a fost următorul pas logic.
Astăzi, fiecare procesor conține mai multe nuclee cu o memorie cache partajată pe cip și o memorie off-chip și are costuri variabile de acces la memorie în diferite părți ale memoriei dintr-un server.
Îmbunătățirea eficienței accesului la date este unul dintre principalele obiective ale designului contemporan al procesorului. Fiecare nucleu CPU a fost dotat cu o memorie cache de nivel mic (32 KB) și o memorie cache de nivel 2 mai mare (256 KB). Diferitele nuclee vor împărtăși mai târziu un cache de nivel 3 de mai mulți MB, a cărui dimensiune a crescut considerabil în timp.
Pentru a evita pierderile din cache - solicitarea de date care nu se află în cache - se petrece mult timp de cercetare pentru a găsi numărul corect de cache-uri CPU, structuri de cache și algoritmi corespunzători. A se vedea [8] pentru o explicație mai detaliată a protocolului pentru cache snoop [4] și coerența cache [3,5], precum și ideile de proiectare din spatele NUMA.
Suport software pentru NUMA
Există două măsuri de optimizare software care pot îmbunătăți performanța unui sistem care acceptă arhitectura NUMA - afinitatea procesorului și plasarea datelor. Așa cum s-a explicat în [19], „afinitatea procesorului […] permite legarea și dezlegarea unui proces sau a unui thread la un singur CPU sau la o gamă de CPU, astfel încât procesul sau firul să se execute doar pe CPU sau CPU-uri desemnate, mai degrabă decât orice CPU.”Termenul„ plasare date ”se referă la modificările software-ului în care codul și datele sunt păstrate cât mai aproape posibil în memorie.
Diferitele sisteme de operare UNIX și UNIX acceptă NUMA în următoarele moduri (lista de mai jos este preluată din [14]):
- Suport IRIX Silicon Graphics pentru arhitectura ccNUMA peste 1240 CPU cu seria server Origin.
- Microsoft Windows 7 și Windows Server 2008 R2 au adăugat suport pentru arhitectura NUMA pe 64 de nuclee logice.
- Versiunea 2.5 din kernel-ul Linux conținea deja suport NUMA de bază, care a fost îmbunătățit în continuare în versiunile ulterioare ale kernel-ului. Versiunea 3.8 din nucleul Linux a adus o nouă fundație NUMA care a permis dezvoltarea unor politici NUMA mai eficiente în versiunile ulterioare ale nucleului [13]. Versiunea 3.13 din kernel-ul Linux a adus numeroase politici care au scopul de a pune un proces în apropierea memoriei sale, împreună cu gestionarea cazurilor, cum ar fi partajarea paginilor de memorie între procese sau utilizarea paginilor imense transparente; noile setări de control al sistemului permit activarea sau dezactivarea echilibrării NUMA, precum și configurarea diferiților parametri de echilibrare a memoriei NUMA [15].
- Atât Oracle, cât și OpenSolaris modelează arhitectura NUMA cu introducerea grupurilor logice.
- FreeBSD a adăugat afinitatea inițială NUMA și configurația politicii în versiunea 11.0.
În cartea „Computer Science and Technology, Proceedings of the International Conference (CST2016)” Ning Cai sugerează că studiul arhitecturii NUMA sa concentrat în principal pe mediul de calcul high-end și a propus partiționarea Radix (NaRP) conștientă de NUMA, care optimizează performanța cache-urilor partajate în nodurile NUMA pentru a accelera aplicațiile de business intelligence. Ca atare, NUMA reprezintă un punct de mijloc între sistemele de memorie partajată (SMP) cu câteva procesoare [6].
NUMA și Linux
După cum sa menționat mai sus, nucleul Linux a acceptat NUMA de la versiunea 2.5. Atât Debian GNU / Linux cât și Ubuntu oferă suport NUMA pentru optimizarea proceselor cu cele două pachete software numactl [16] și numad [17]. Cu ajutorul comenzii numactl, puteți lista inventarul de noduri NUMA disponibile în sistemul dumneavoastră [18]:
# numactl --hardwaredisponibil: 2 noduri (0-1)
nod 0 cpus: 0 1 2 3 4 5 6 7 16 17 18 19 20 21 22 23
dimensiunea nodului 0: 8157 MB
nod 0 liber: 88 MB
nodul 1 cpus: 8 9 10 11 12 13 14 15 24 25 26 27 28 29 30 31
dimensiunea nodului 1: 8191 MB
nodul 1 gratuit: 5176 MB
distanțele nodului:
nod 0 1
0: 10 20
1: 20 10
NumaTop este un instrument util dezvoltat de Intel pentru monitorizarea localității memoriei runtime și analiza proceselor din sistemele NUMA [10,11]. Instrumentul poate identifica potențiale blocaje de performanță legate de NUMA și, prin urmare, poate ajuta la reechilibrarea alocărilor de memorie / CPU pentru a maximiza potențialul unui sistem NUMA. A se vedea [9] pentru o descriere mai detaliată.
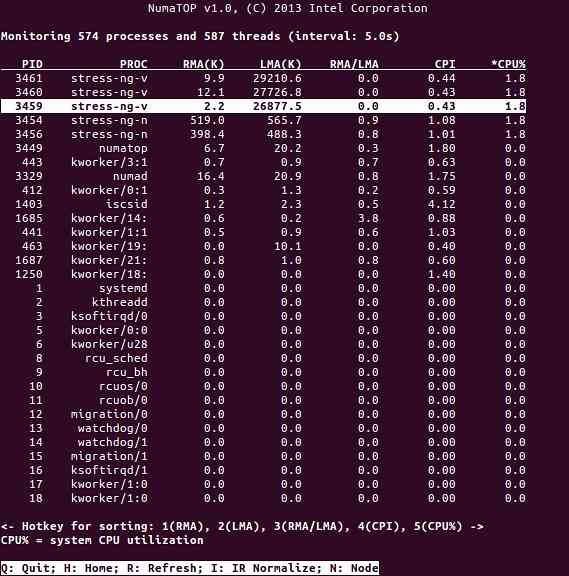
Scenarii de utilizare
Calculatoarele care acceptă tehnologia NUMA permit tuturor CPU-urilor să acceseze direct întreaga memorie - CPU-urile văd acest lucru ca un spațiu de adresare unic, liniar. Acest lucru duce la o utilizare mai eficientă a schemei de adresare pe 64 de biți, rezultând o mișcare mai rapidă a datelor, o mai mică replicare a datelor și o programare mai ușoară.
Sistemele NUMA sunt destul de atractive pentru aplicațiile de pe server, cum ar fi extragerea datelor și sistemele de suport pentru decizii. Mai mult, scrierea aplicațiilor pentru jocuri și software de înaltă performanță devine mult mai ușoară cu această arhitectură.
Concluzie
În concluzie, arhitectura NUMA abordează scalabilitatea, care este unul dintre principalele sale beneficii. Într-un procesor NUMA, un nod va avea o lățime de bandă mai mare sau o latență mai mică pentru a accesa memoria de pe același nod (e.g., CPU local solicită acces la memorie în același timp cu accesul de la distanță; prioritatea este pe CPU local). Acest lucru va îmbunătăți dramatic capacitatea de memorie dacă datele sunt localizate la anumite procese (și astfel la procesoare). Dezavantajele sunt costurile mai mari ale mutării datelor de la un procesor la altul. Atâta timp cât acest caz nu se întâmplă prea des, un sistem NUMA va depăși sistemele cu o arhitectură mai tradițională.
Linkuri și referințe
- Comparați NVIDIA Tesla vs. Radeon Instinct, https: // www.stația centrală.com / products / comparisons / nvidia-tesla_vs_radeon-instinct
- Comparați NVIDIA DGX-1 vs. Radeon Instinct, https: // www.stația centrală.com / products / comparisons / nvidia-dgx-1_vs_radeon-instinct
- Coerența cache-ului, Wikipedia, https: // ro.wikipedia.org / wiki / Cache_coherence
- Bus snooping, Wikipedia, https: // ro.wikipedia.org / wiki / Bus_snooping
- Protocoale de coerență a memoriei cache în sistemele multiprocesor, Geeks pentru geeks, https: // www.geeksforgeeks.org / cache-coherence-protocols-in-multiprocessor-system /
- Informatică și tehnologie - Lucrările Conferinței Internaționale (CST2016), Ning Cai (Ed.), World Scientific Publishing Co Pte Ltd, ISBN: 9789813146419
- Daniel P. Bovet și Marco Cesati: Înțelegerea arhitecturii NUMA în Înțelegerea nucleului Linux, ediția a 3-a, O'Reilly, https: // www.oreilly.com / library / view / understand-the-linux / 0596005652 /
- Frank Dennemann: NUMA Deep Dive Partea 1: De la UMA la NUMA, https: // frankdenneman.nl / 2016/07/07 / numa-deep-dive-part-1-uma-numa /
- Colin Ian King: NumaTop: Un instrument de monitorizare a sistemului NUMA, http: // smackerelofopinion.blogspot.com / 2015/09 / numatop-numa-system-monitoring-tool.html
- Numatop, https: // github.com / intel / numatop
- Numatop pachet pentru Debian GNU / Linux, pachete https: //.debian.org / buster / numatop
- Jonathan Kehayias: Understanding Non-Uniform Memory Access / Architectures (NUMA), https: // www.sqlskills.com / bloguri / Jonathan / understand-non-uniform-memory-accessarchitectures-numa /
- Știri Kernel Linux pentru Kernel 3.8, https: // kernelnewbies.org / Linux_3.8
- Acces neuniform la memorie (NUMA), Wikipedia, https: // ro.wikipedia.org / wiki / Non-uniform_memory_access
- Documentație de gestionare a memoriei Linux, NUMA, https: // www.nucleu.org / doc / html / latest / vm / numa.html
- Pachet numactl pentru Debian GNU / Linux, pachete https: //.debian.org / sid / admin / numactl
- Numad pachet pentru Debian GNU / Linux, pachete https: //.debian.org / buster / numad
- Cum să aflați dacă configurația NUMA este activată sau dezactivată?, https: // www.thegeekdiary.com / centos-rhel-how-to-find-if-numa-configuration-is-enabled-or-disabled /
- Afinitate procesor, Wikipedia, https: // ro.wikipedia.org / wiki / Processor_affinity
Mulțumesc
Autorii ar dori să mulțumească lui Gerold Rupprecht pentru sprijinul acordat în timpul pregătirii acestui articol.
despre autori
Plaxedes Nehanda este o persoană versatilă cu multe abilități, auto-condusă, care poartă multe pălării, printre care, un planificator de evenimente, un asistent virtual, un transcriptor, precum și un cercetător avid, cu sediul în Johannesburg, Africa de Sud.
Prințul K. Nehanda este inginer instrumentar și control (metrologie) la Paeflow Metering din Harare, Zimbabwe.
Frank Hofmann lucrează pe drum - de preferință din Berlin (Germania), Geneva (Elveția) și Cape Town (Africa de Sud) - ca dezvoltator, trainer și autor pentru reviste precum Linux-User și Linux Magazine. El este, de asemenea, co-autorul cărții Debian de gestionare a pachetelor (http: // www.dpmb.org).


