Pandas .read_csv
I have already discussed some of the history and uses for the Python library pandas. pandas was designed out of the need for an efficient financial data analysis and manipulation library for Python. In order to load data for analysis and manipulation, pandas provides two methods, DataReader and read_csv. I covered the first here. The latter is the subject of this tutorial.
.read_csv
There are a large number of free data repositories online that include information on a variety of fields. I have included some of those resources in the references section below. Because I have demonstrated the built-in APIs for efficiently pulling financial data here, I will use another source of data in this tutorial.
Data.gov offers a huge selection of free data on everything from climate change to U.S. manufacturing statistics. I have downloaded two data sets for use in this tutorial. The first is the mean daily maximum temperature for Bay County, Florida. This data was downloaded from the U.S. Climate Resilience Toolkit for the period of 1950 to current.
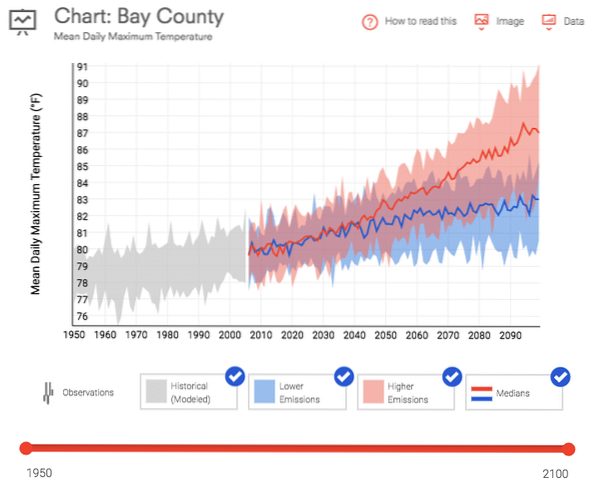
The second is the Commodity Flow Survey which measures the mode and volume of imports into the country over a 5 year period.

Both of the links for these data sets are provided in the references section below. The .read_csv method, as is clear from the name, will load this information in from a CSV file and instantiate a DataFrame out of that data set.
Usage
Any time you use an external library, you need to tell Python that it needs to be imported. Below is the line of code that imports the pandas library.
import pandas as pdThe basic usage of the .read_csv method is below. This instantiates and populates a DataFrame df with the information in the CSV file.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')By adding a couple more lines, we can inspect the first and last 5 lines from the newly created DataFrame.
df = pd.read_csv('12005-annual-hist-obs-tasmax.csv')print(df.head(5))
print(df.tail(5))

The code has loaded a column for year, the mean daily temperature in Celsius (tasmax), and constructed a 1-based indexing scheme that increments for each line of data. It is also important to note that the headers are populated from the file. With the basic use of the method presented above, the headers are inferred to be on the first line of the CSV file. This can be changed by passing a different set of parameters to the method.
Parameters
I have provided the link to the pandas .read_csv documentation in the references below. There are several parameters that can be used to alter the way the data is read and formatted in the DataFrame.

There are a fair number of parameters for the .read_csv method. Most are not necessary because most of the datasets that you download will have a standard format. That is columns on the first row and a comma delimiter.
There are a couple of parameters that I will highlight in the tutorial because they can be useful. A more comprehensive survey can be taken from the documentation page.
index_col
index_col is a parameter that can be used to indicate the column that holds the index. Some files may contain an index and some may not. In our first data set, I let python create an index. This is the standard .read_csv behavior.
In our second data set, there is an index included. The code below loads the DataFrame with the data in the CSV file, but instead of creating an incremental integer based index it uses the SHPMT_ID column included in the data set.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col = 'SHIPMT_ID')print(df.head(5))
print(df.tail(5))
While this dataset uses the same scheme for the index, other datasets may have a more useful index.
nrows, skiprows, usecols
With large datasets you may only want to load sections of the data. The nrows, skiprows, and usecols parameters will allow you to slice the data included in the file.
df = pd.read_csv('cfs_2012_pumf_csv.txt', index_col= 'SHIPMT_ID', nrows = 50)print(df.head(5))
print(df.tail(5))
By adding the nrows parameter with an integer value of 50, the .tail call now returns lines up to 50. The rest of the data in the file is not imported.
print(df.head(5))
print(df.tail(5))
By adding the skiprows parameter, our .head col is not showing a beginning index of 1001 in the data. Because we skipped the header row, the new data has lost its header and the index based on the file data. In some cases, it may be better to slice your data in a DataFrame rather than before loading the data.

The usecols is a useful parameter that allows you to import only a subset of the data by column. It can be passed a zeroth index or a list of strings with the column names. I used the code below to import the first four columns into our new DataFrame.
df = pd.read_csv('cfs_2012_pumf_csv.txt',index_col = 'SHIPMT_ID',
nrows = 50, usecols = [0,1,2,3] )
print(df.head(5))
print(df.tail(5))
From our new .head call, our DataFrame now only contains the first four columns from the dataset.
engine
One last parameter that I think would come in handy in some datasets is the engine parameter. You can use either the C based engine or the Python based code. The C engine will naturally be faster. This is important if you are importing large datasets. The benefits of the Python parsing are a more feature rich set. This benefit may mean less if you are loading big data into memory.
df = pd.read_csv('cfs_2012_pumf_csv.txt',index_col = 'SHIPMT_ID', engine = 'c' )
print(df.head(5))
print(df.tail(5))
Follow up
There are several other parameters that can extend the default behavior of the .read_csv method. They can be found on the docs page that I referenced below. .read_csv is a useful method for loading datasets into pandas for data analysis. Because many of the free datasets on the internet do not have APIs, this will prove most useful for applications outside of financial data where robust APIs are in place to import data into pandas.
References
https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html
https://www.data.gov/
https://toolkit.climate.gov/#climate-explorer
https://www.census.gov/econ/cfs/pums.html


