De exemplu, dacă doriți să primiți actualizări regulate la produsele preferate pentru oferte de reducere sau doriți să automatizați procesul de descărcare a episoadelor sezonului preferat unul câte unul, iar site-ul web nu are niciun API pentru acesta, atunci singura alegere rămâneți cu răzuirea web.Răzuirea web poate fi ilegală pe unele site-uri web, în funcție de faptul dacă un site web permite sau nu. Site-urile folosesc „roboți.txt ”pentru a defini în mod explicit adresele URL care nu pot fi casate. Puteți verifica dacă site-ul web permite sau nu adăugând „roboți”.txt ”cu numele de domeniu al site-ului web. De exemplu, https: // www.Google.com / roboți.txt
În acest articol, vom folosi Python pentru răzuire, deoarece este foarte ușor de configurat și de utilizat. Are multe biblioteci încorporate și terțe, care pot fi utilizate pentru răzuirea și organizarea datelor. Vom folosi două biblioteci Python „urllib” pentru a prelua pagina web și „BeautifulSoup” pentru a analiza pagina web pentru a aplica operațiuni de programare.
Cum funcționează Web Scraping?
Trimitem o solicitare către pagina web, de unde doriți să răscoliți datele. Site-ul web va răspunde cererii cu conținut HTML al paginii. Apoi, putem analiza această pagină web la BeautifulSoup pentru procesare ulterioară. Pentru a prelua pagina web, vom folosi biblioteca „urllib” în Python.
Urllib va descărca conținutul paginii web în HTML. Nu putem aplica operații de șir la această pagină web HTML pentru extragerea conținutului și procesarea ulterioară. Vom folosi o bibliotecă Python „BeautifulSoup” care va analiza conținutul și va extrage datele interesante.
Scraping articole din Linuxhint.com
Acum, că avem o idee despre cum funcționează răzuirea web, să facem câteva practici. Vom încerca să răscumpărăm titlurile articolelor și linkurile din Linuxhint.com. Deci, deschideți https: // linuxhint.com / în browserul dvs.
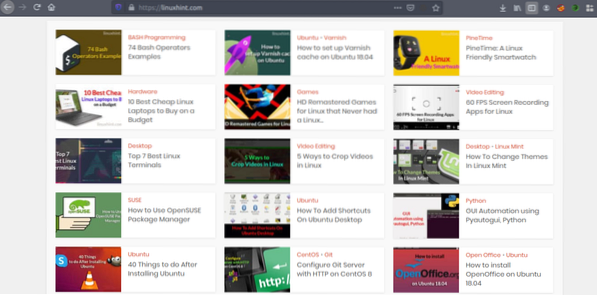
Acum apăsați CRTL + U pentru a vizualiza codul sursă HTML al paginii web.
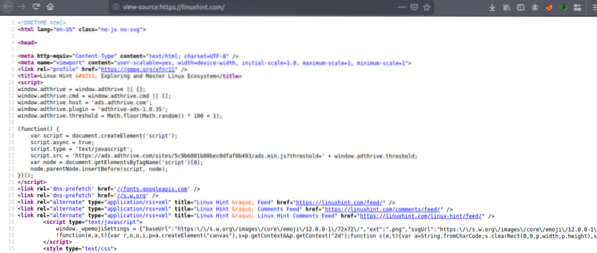
Copiați codul sursă și accesați https: // htmlformatter.com / pentru a prettifica codul. După verificarea codului, este ușor să inspectați codul și să găsiți informații interesante.
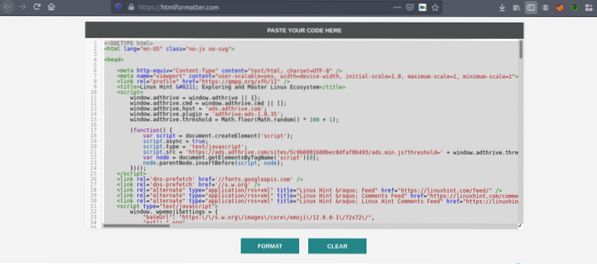
Acum, copiați din nou codul formatat și lipiți-l în editorul de text preferat, cum ar fi atom, text sublim etc. Acum vom răzuie informațiile interesante folosind Python. Tastați următoarele
// Instalați o frumoasă bibliotecă de supe, urllib vinepreinstalat în Python
ubuntu @ ubuntu: ~ $ sudo pip3 instalați bs4
ubuntu @ ubuntu: ~ $ python3
Python 3.7.3 (implicit, 7 octombrie 2019, 12:56:13)
[GCC 8.3.0] pe linux
Tastați „ajutor”, „drepturi de autor”, „credite” sau „licență” pentru mai multe informații.
// Importă urllib>>> import urllib.cerere
// Importă BeautifulSoup
>>> din importul BSS BeautifulSoup
// Introduceți adresa URL pe care doriți să o preluați
>>> my_url = 'https: // linuxhint.com / '
// Solicitați pagina web URL utilizând comanda urlopen
>>> client = urllib.cerere.urlopen (my_url)
// Stocați pagina web HTML în variabila „html_page”
>>> html_page = client.citit()
// Închideți conexiunea URL după preluarea paginii web
>>> client.închide()
// analizați pagina web HTML în BeautifulSoup pentru răzuire
>>> page_soup = BeautifulSoup (html_page, "html.analizor ")
Acum să ne uităm la codul sursă HTML pe care tocmai l-am copiat și lipit pentru a găsi lucruri de interesul nostru.
Puteți vedea că primul articol listat pe Linuxhint.com se numește „74 Exemple de operatori Bash”, găsiți acest lucru în codul sursă. Este inclus între etichetele de antet, iar codul său este
title = "74 Exemple de operatori Bash"> 74 Operatori Bash
Exemple
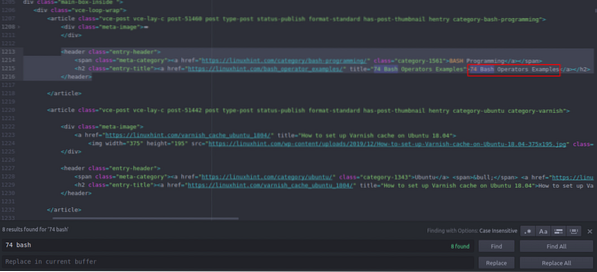
Același cod se repetă iar și iar cu schimbarea doar a titlurilor articolelor și a linkurilor. Următorul articol are următorul cod HTML
title = "Cum se configurează memoria cache Varnish pe Ubuntu 18.04 ">
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
Puteți vedea că toate articolele, inclusiv aceste două, sunt incluse în același „
”Și utilizați aceeași clasă„ entry-title ”. Putem folosi funcția „findAll” din biblioteca Beautiful Soup pentru a găsi și enumera toate „”Având clasa„ entry-title ”. Tastați următoarele în consola Python // Această comandă va găsi toate „”Etichetați elemente cu clasă numită
„Titlu-intrare”. Ieșirea va fi stocată într-o matrice.
>>> articole = page_soup.findAll ("h2" ,
"class": "entry-title")
// Numărul de articole găsite pe prima pagină a Linuxhint.com
>>> len (articole)
102
// Primul extras „”Element de etichetă care conține numele articolului și link-ul
>>> articole [0]
title = "74 Exemple de operatori Bash">
74 Exemple de operatori Bash
// Al doilea extras „”Element de etichetă care conține numele articolului și link-ul
>>> articole [1]
title = "Cum se configurează memoria cache Varnish pe Ubuntu 18.04 ">
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
// Afișarea numai textului în etichete HTML utilizând funcția text
>>> articole [1].text
„Cum se configurează cache-ul Varnish pe Ubuntu 18.04 '
”Etichetați elemente cu clasă numită
„Titlu-intrare”. Ieșirea va fi stocată într-o matrice.
>>> articole = page_soup.findAll ("h2" ,
"class": "entry-title")
// Numărul de articole găsite pe prima pagină a Linuxhint.com
>>> len (articole)
102
// Primul extras „”Element de etichetă care conține numele articolului și link-ul
>>> articole [0]
title = "74 Exemple de operatori Bash">
74 Exemple de operatori Bash
// Al doilea extras „”Element de etichetă care conține numele articolului și link-ul
>>> articole [1]
title = "Cum se configurează memoria cache Varnish pe Ubuntu 18.04 ">
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
// Afișarea numai textului în etichete HTML utilizând funcția text
>>> articole [1].text
„Cum se configurează cache-ul Varnish pe Ubuntu 18.04 '
>>> articole [0]
title = "74 Exemple de operatori Bash">
74 Exemple de operatori Bash
// Al doilea extras „
”Element de etichetă care conține numele articolului și link-ul
>>> articole [1]
title = "Cum se configurează memoria cache Varnish pe Ubuntu 18.04 ">
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
// Afișarea numai textului în etichete HTML utilizând funcția text
>>> articole [1].text
„Cum se configurează cache-ul Varnish pe Ubuntu 18.04 '
title = "Cum se configurează memoria cache Varnish pe Ubuntu 18.04 ">
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
Acum că avem o listă cu toate cele 102 HTML „
”Elemente de etichetă care conține linkul articolului și titlul articolului. Putem extrage atât linkuri de articole, cât și titluri. Pentru a extrage linkuri din „”, Putem folosi următorul cod // Următorul cod va extrage linkul din prima element de etichetă
>>> pentru link în articole [0].find_all ('a', href = True):
… Tipăriți (link ['href'])
..
https: // linuxhint.com / bash_operator_examples /
Acum putem scrie o buclă for care iterează prin fiecare „
Element de etichetă ”din lista„ articole ”și extrageți linkul articolului și titlul. >>> pentru i în interval (0,10):
... tipărire (articole [i].text)
... pentru link în articole [i].find_all ('a', href = True):
... print (link ['href'] + "\ n")
..
74 Exemple de operatori Bash
https: // linuxhint.com / bash_operator_examples /
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: un ceas inteligent prietenos cu Linux
https: // linuxhint.com / pinetime_linux_smartwatch /
Cele mai bune 10 laptopuri ieftine Linux pentru a cumpăra la un buget
https: // linuxhint.com / best_cheap_linux_laptops /
Jocuri HD remasterizate pentru Linux care nu au avut niciodată lansarea Linux ..
https: // linuxhint.com / hd_remastered_games_linux /
60 de aplicații de înregistrare a ecranului FPS pentru Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Exemple de operatori Bash
https: // linuxhint.com / bash_operator_examples /
... trage ..
În mod similar, salvați aceste rezultate într-un fișier JSON sau CSV.
Concluzie
Sarcinile dvs. zilnice nu sunt doar gestionarea fișierelor sau executarea comenzilor de sistem. De asemenea, puteți automatiza sarcini legate de web, cum ar fi automatizarea descărcării fișierelor sau extragerea datelor, răzuind webul în Python. Acest articol a fost limitat doar la extragerea simplă a datelor, dar puteți realiza automatizarea imensă a sarcinilor folosind „urllib” și „BeautifulSoup”.
>>> pentru link în articole [0].find_all ('a', href = True):
… Tipăriți (link ['href'])
..
https: // linuxhint.com / bash_operator_examples /
... tipărire (articole [i].text)
... pentru link în articole [i].find_all ('a', href = True):
... print (link ['href'] + "\ n")
..
74 Exemple de operatori Bash
https: // linuxhint.com / bash_operator_examples /
Cum se configurează memoria cache Varnish pe Ubuntu 18.04
https: // linuxhint.com / varnish_cache_ubuntu_1804 /
PineTime: un ceas inteligent prietenos cu Linux
https: // linuxhint.com / pinetime_linux_smartwatch /
Cele mai bune 10 laptopuri ieftine Linux pentru a cumpăra la un buget
https: // linuxhint.com / best_cheap_linux_laptops /
Jocuri HD remasterizate pentru Linux care nu au avut niciodată lansarea Linux ..
https: // linuxhint.com / hd_remastered_games_linux /
60 de aplicații de înregistrare a ecranului FPS pentru Linux
https: // linuxhint.com / 60_fps_screen_recording_apps_linux /
74 Exemple de operatori Bash
https: // linuxhint.com / bash_operator_examples /
... trage ..


