Înainte de a utiliza tabelul pivot al panda, asigurați-vă că vă înțelegeți datele și întrebările pe care încercați să le rezolvați prin intermediul tabelului pivot. Utilizând această metodă, puteți produce rezultate puternice. În acest articol vom detalia cum să creați un tabel pivot în python pandas.
Citiți date din fișier Excel
Am descărcat o bază de date Excel a vânzărilor de alimente. Înainte de a începe implementarea, trebuie să instalați câteva pachete necesare pentru citirea și scrierea fișierelor bazei de date Excel. Tastați următoarea comandă în secțiunea terminal a editorului dvs. Pycharm:
pip instala xlwt openpyxl xlsxwriter xlrd
Acum, citiți datele din foaia Excel. Importați bibliotecile panda necesare și modificați calea bazei de date. Apoi, executând următorul cod, datele pot fi preluate din fișier.
import panda ca pdimport numpy ca np
dtfrm = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
print (dtfrm)
Aici, datele sunt citite din baza de date Excel pentru vânzările de alimente și transmise în variabila cadru de date.
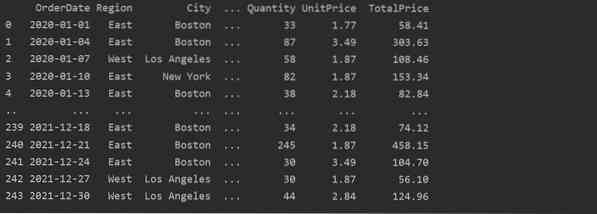
Creați un tabel pivot folosind Pandas Python
Mai jos am creat un simplu tabel pivot utilizând baza de date de vânzare a produselor alimentare. Pentru a crea un tabel pivot sunt necesari doi parametri. Primul este datele pe care le-am transmis în cadrul de date, iar celălalt este un index.
Pivotați datele pe un index
Indexul este caracteristica unui tabel pivot care vă permite să grupați datele pe baza cerințelor. Aici, am luat „Produs” ca index pentru a crea un tabel pivot de bază.
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ["Produs"])
print (pivot_tble)
Următorul rezultat se afișează după executarea codului sursă de mai sus:
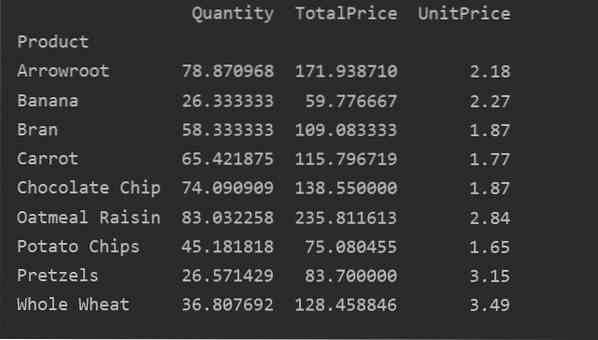
Definiți în mod explicit coloanele
Pentru mai multe analize ale datelor dvs., definiți în mod explicit numele coloanelor cu indexul. De exemplu, dorim să afișăm în rezultat singurul preț unitar al fiecărui produs. În acest scop, adăugați parametrul de valori în tabelul pivot. Următorul cod vă oferă același rezultat:
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = 'Produs', valori = 'UnitPrice')
print (pivot_tble)
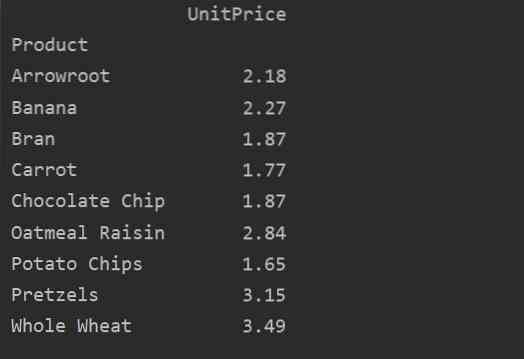
Pivotați datele cu index multiplu
Datele pot fi grupate pe baza mai multor caracteristici ca index. Utilizând abordarea multi-index, puteți obține rezultate mai specifice pentru analiza datelor. De exemplu, produsele se încadrează în diferite categorii. Deci, puteți afișa indicele „Produs” și „Categorie” cu „Cantitate” și „Preț unit” disponibile pentru fiecare produs, după cum urmează:
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], values = ["UnitPrice", "Quantity"])
print (pivot_tble)
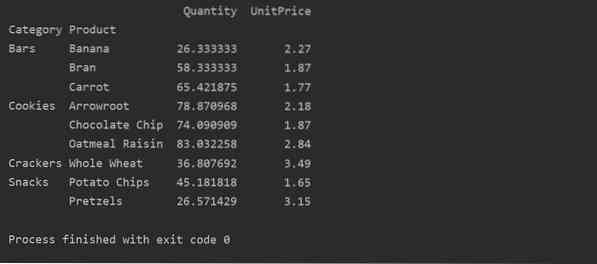
Aplicarea funcției de agregare în tabelul pivot
Într-un tabel pivot, aggfunc poate fi aplicat pentru diferite valori ale caracteristicii. Tabelul rezultat este rezumarea datelor despre caracteristici. Funcția agregată se aplică datelor grupului dvs. din tabelul pivot. În mod implicit, funcția agregată este np.Rău(). Dar, pe baza cerințelor utilizatorilor, se pot aplica diferite funcții agregate pentru diferite caracteristici de date.
Exemplu:
Am aplicat funcții agregate în acest exemplu. Np.funcția sum () este utilizată pentru caracteristica „Cantitate” și np.funcția mean () pentru caracteristica „UnitPrice”.
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
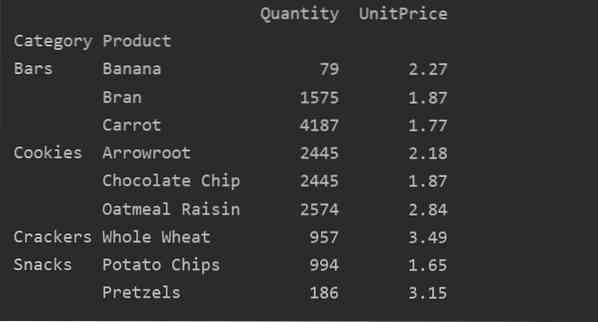
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], aggfunc = 'Cantity': np.sumă, „UnitPrice”: np.Rău)
print (pivot_tble)
După aplicarea funcției de agregare pentru diferite caracteristici, veți obține următoarea ieșire:
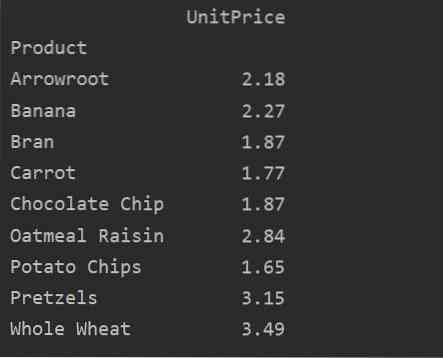
Folosind parametrul valoare, puteți aplica, de asemenea, funcția agregată pentru o anumită caracteristică. Dacă nu specificați valoarea caracteristicii, aceasta agregează caracteristicile numerice ale bazei de date. Urmând codul sursă dat, puteți aplica funcția agregată pentru o anumită caracteristică:
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ['Produs'], valori = ['UnitPrice'], aggfunc = np.Rău)
print (pivot_tble)
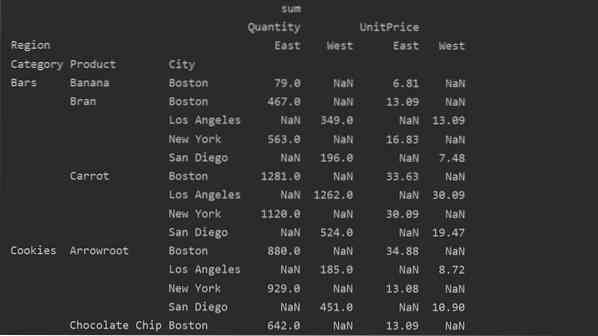
Diferit între valori vs. Coloane din tabelul pivot
Valorile și coloanele sunt principalul punct confuz din tabelul pivot. Este important să rețineți că coloanele sunt câmpuri opționale, afișând valorile tabelului rezultat orizontal în partea de sus. Funcția de agregare aggfunc se aplică câmpului de valori pe care îl listați.
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
coloane = ['Regiune'], aggfunc = [np.sumă])
print (pivot_tble)
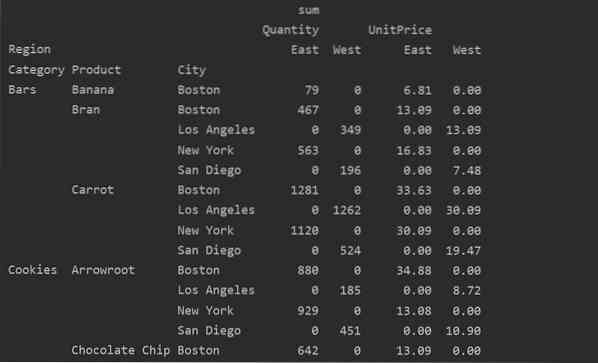
Gestionarea datelor lipsă în tabelul pivot
De asemenea, puteți gestiona valorile lipsă din tabelul pivot utilizând 'fill_value' Parametru. Acest lucru vă permite să înlocuiți valorile NaN cu unele noi valori pe care le oferiți pentru a le completa.
De exemplu, am eliminat toate valorile nule din tabelul rezultant de mai sus rulând următorul cod și înlocuim valorile NaN cu 0 în întregul tabel rezultant.
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ')
pivot_tble = pd.pivot_table (dataframe, index = ['Category', 'Product', 'City'], values = ['UnitPrice', 'Quantity'],
coloane = ['Regiune'], aggfunc = [np.sumă], valoare_umplere = 0)
print (pivot_tble)
Filtrarea în tabelul pivot
Odată ce rezultatul este generat, puteți aplica filtrul utilizând funcția standard cadru de date. Să luăm un exemplu. Filtrați produsele al căror preț unitar este mai mic de 60. Afișează acele produse al căror preț este mai mic de 60.
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (dataframe, index = 'Produs', valori = 'UnitPrice', aggfunc = 'sumă')
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
print (low_price)

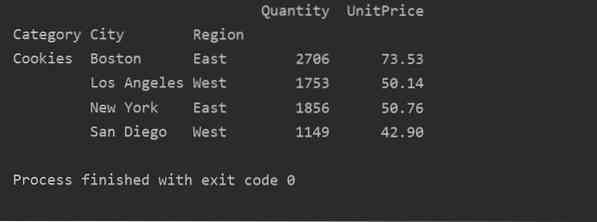
Utilizând o altă metodă de interogare, puteți filtra rezultatele. De exemplu, De exemplu, am filtrat categoria cookie-urilor pe baza următoarelor caracteristici:
import panda ca pdimport numpy ca np
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "City", "Region"], values = ["UnitPrice", "Quantity"], aggfunc = np.sumă)
pt = pivot_tble.interogare ('Category == ["Cookies"]')
print (pt)
Ieșire:
Vizualizați datele din tabelul pivot
Pentru a vizualiza datele din tabelul pivot, urmați următoarea metodă:
import panda ca pdimport numpy ca np
import matplotlib.pyplot ca plt
cadru de date = pd.read_excel ('C: / Users / DELL / Desktop / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.pivot_table (dataframe, index = ["Category", "Product"], values = ["UnitPrice"])
pivot_tble.complot (kind = 'bar');
plt.spectacol()
În vizualizarea de mai sus, am arătat prețul unitar al diferitelor produse împreună cu categoriile.

Concluzie
Am explorat modul în care puteți genera un tabel pivot din cadrul de date folosind Python Python. Un tabel pivot vă permite să generați informații detaliate asupra seturilor de date. Am văzut cum să generăm un tabel pivot simplu folosind multi-index și să aplicăm filtrele pe tabelele pivot. Mai mult, am arătat, de asemenea, să trasăm datele din tabelul pivot și să completăm datele lipsă.


