The world wide web is the all-encompassing and ultimate source of all the data there is. The rapid development that the internet has seen in the past three decades has been unprecedented. As a result, the web is being mounted with hundreds of terabytes of data every passing day.
All of this data has some value for a certain someone. For example, your browsing history holds significance for social media apps, as they use it to personalize the advertisements they show you. And there's a lot of competition for this data as well; a few MBs more of some data can give businesses a substantial edge over their competition.
Data mining with Python
To help those of you who're new to data scraping, we've prepared this guide in which we'll show how to scrape data from the web using Python and Beautiful soup Library.
We're assuming that you already have intermediate familiarity with Python and HTML, as you'll be working with both of these following the instructions in this guide.
Be cautious about which sites you're trying your newfound data mining skills on, as many sites consider this intrusive and know that there could be repercussions.
Installing and preparing the Libraries
Now, we're going to use two libraries that we're going to use: python's request library for loading contents off of web pages and the Beautiful Soup library for the actual scraping bit of the process. There are alternatives to BeautifulSoup, mind you, and if you're familiar with any one of the following, feel free to use these instead: Scrappy, Mechanize, Selenium, Portia, kimono, and ParseHub.
The request library can be downloaded and installed with the pip command as under:
# pip3 install requests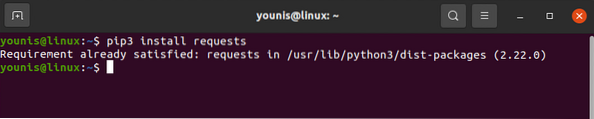
The request library should be installed on your device. Similarly, download BeautifulSoup as well:
# pip3 install beautifulsoup4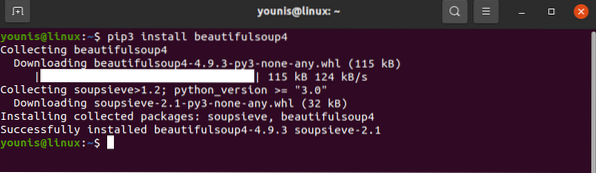
With that, our libraries are ready for some action.
As mentioned above, the request library doesn't have much use other than fetching the contents off of webpages. The BeautifulSoup library and requests libraries have a place in every script that you're going to write, and they have to be imported before each as follows:
$import requests$from bs4 import BeautifulSoup as bs
This adds the requested keyword to the namespace, signaling to Python the keyword's meaning whenever its use is prompted. The same thing happens to the bs keyword, though here we have the benefit of assigning a simpler keyword for BeautifulSoup.
webpage = requests.get(URL)The code above fetches the webpage URL and creates a direct string out of it, storing it into a variable.
$webcontent = webpage.contentThe command above copies the webpage's contents and assigns them to the variable web content.
With that, we're done with the request library. All there's left to do is change the request library options into BeautifulSoup options.
$htmlcontent = bs(webcontent, “html.parser“)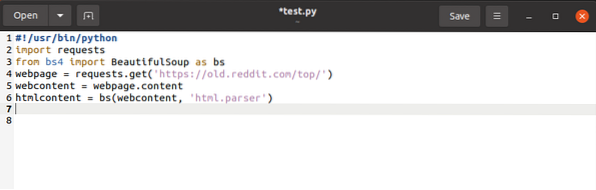
This parses the request object and turns it into readable HTML objects.
With that all taken care of, we can move on to the actual scraping bit.
Web scraping with Python and BeautifulSoup
Let's move on and see how we can scrape for data HTML objects with BeautifulSoup.
To illustrate an example, while we explain things, we'll work with this html snippet:
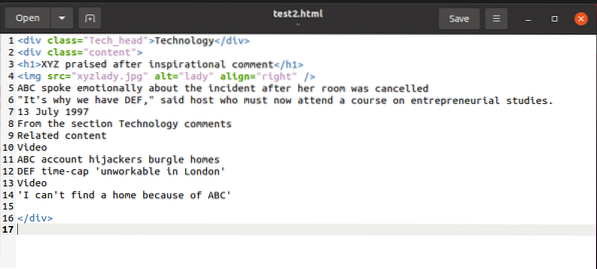
We can access the contents of this snippet with BeautifulSoup and use it on the HTML content variable as under:
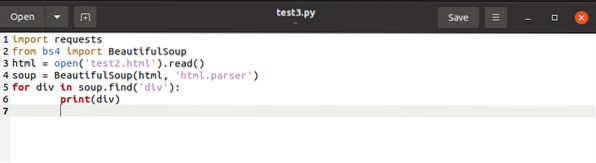
The code above searches for any tags named
To simultaneously save the tags named
to a list, we'd issue the final code as under: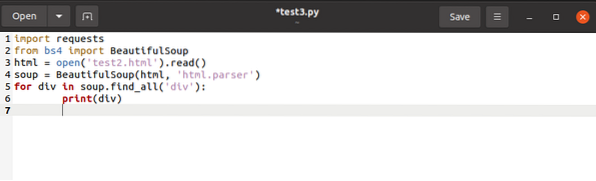
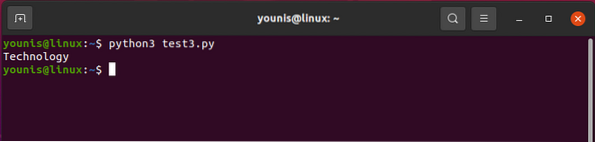
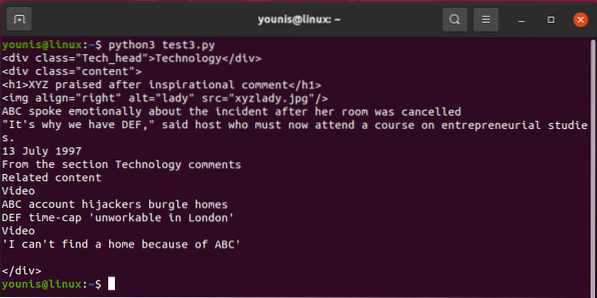
The output should return like this:
To summon one of the
Now lets see how to pick out
tags keeping in perspective their characteristics. To separate a , we'd need the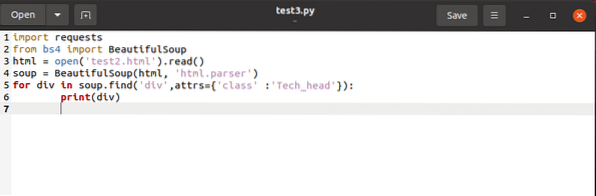
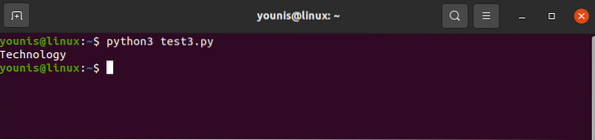
for div in soup.find_all('div',attrs='class'='Tech_head'):
This fetches the
tag.You'd get:
Technology
All without tags.
Lastly, we will cover how to pick out the attribute's value in a tag. The code should have this tag:
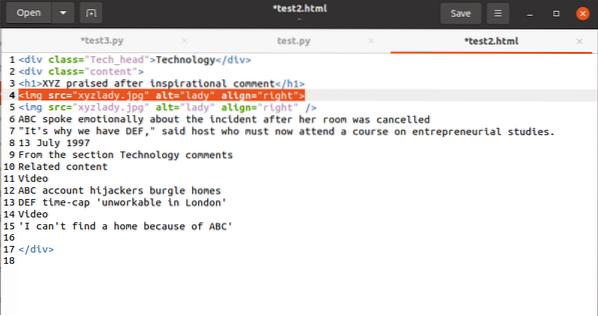

To operate out the value associated with the src attribute, you'd use the following:
htmlcontent.find(“img“)[“src“]And the output would turn out as:
"images_4/a-beginners-guide-to-web-scraping-with-python-and-beautiful-soup.jpg"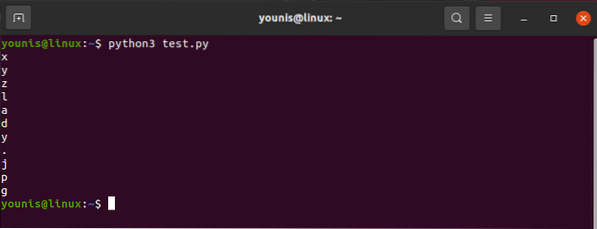
Oh boy, that sure is a whole lot of work!
If you feel your familiarity with python or HTML is inadequate or if you're simply overwhelmed with the web scraping, don't worry.
If you're a business that needs to acquire a particular type of data regularly but cannot do the web-scraping yourself, there are ways around this problem. But know that it's going to cost you some money. You can find someone to do the scraping for you, or you can get the premium data service from websites like Google and Twitter to share the data with you. These share portions of their data by employing APIs, but these API calls are limited per day. Aside from that, websites such as these can be very protective of their data. Typically many such sites do not share any of their data at all.
Final thoughts
Before we wrap up, let me tell you out loud if it hasn't been self-evident already; the find(), find_all() commands are your best friends when you're out scraping with BeautifulSoup. Though theree's a whole lot more to cover to master data scraping with Python, this guide should be enough for those of you just starting.

